Creating crawl jobs (Section 5.1, “Crawl job”) and profiles (Section 5.2, “Profile”) is just the first step. Configuring them is a more complicated process.
The following section applies equally to configuring crawl jobs and profiles. It does not matter if new ones are being created or existing ones are being edited. The interface is almost entirely the same, only the Submit job / Finished button will vary.
Note
Editing options for jobs being crawled are somewhat limited. See Section 7.4, “Editing a running job” for more.
Each page in the configuration section of the WUI will have a secondary row of tabs below the general ones. This secondary row is often replicated at the bottom of longer pages.
This row offers access to different parts of the configuration. While configuring the global level (more on global vs. overrides and refinements in Section 6.4, “Overrides” and Section 6.5, “Refinements”) the following options are available (left to right):
Modules (Section 6.1, “Modules (Scope, Frontier, and Processors)”)
Add/remove/set configurable modules, such as the crawl Scope (Section 6.1.1, “Crawl Scope”), Frontier (Section 6.1.2, “Frontier”), or Processors (Section 6.1.3, “Processing Chains”).
Submodules (Section 6.2, “Submodules”)
Here you can:
Add/remove/reorder URL canonicalization rules (Section 6.2.1, “URL Canonicalization Rules”)
Add/remove/reorder filters (Section 6.2.2, “Filters”)
Add/remove login credentials (Section 6.2.3, “Credentials”)
Settings (Section 6.3, “Settings”)
Configure settings on Heritrix modules
Overrides (Section 6.4, “Overrides”)
Override settings on Heritrix modules based on domain
Refinements (Section 6.5, “Refinements”)
Refine settings on Heritrix modules based on arbitrary criteria
Submit job / Finished
Clicking this tab will take the user back to the Jobs or Profiles page, saving any changes.
The Settings tab is probably the most frequently used page as it allows the user to fine tune the settings of any Heritrix module used in a job or profile.
It is safe to navigate between these, it will not cause new jobs to be submitted to the queue of pending jobs. That only happens once the Submit job tab is clicked. Navigating out of the configuration pages using the top level tabs will cause new jobs to be lost. Any changes made are saved when navigating within the configuration pages. There is no undo function, once made changes can not be undone.
Heritrix has several types of pluggable modules. These modules, while having a fixed interface usually have a number of provided implementations. They can also be third party plugins. The "Modules" tab allows the user to set several types of these pluggable modules.
Once modules have been added to the configuration they can be configured in greater detail on the Settings tab (Section 6.3, “Settings”). If a module can contain within it multiple other modules, these can be configured on the Submodules tab.
Note
Modules are referred to by their Java class names (org.archive.crawler.frontier.BdbFrontier). This is done because these are the only names we can be assured of being unique.
A crawl scope is an object that decides for each discovered URI if it is within the scope of the current crawl.
Several scopes are provided with Heritrix:
BroadScope
This scope allows for limiting the depth of a crawl (how many links away Heritrix should crawl) but does not impose any limits on the hosts, domains, or URI paths crawled.
A highly flexible and fairly efficient scope which can crawl within defined domains, individual hosts, or path-defined areas of hosts, or any mixture of those, depending on the configuration.
It considers whether any URI is inside the primary focus of the scope by converting the URI to its SURT form, and then seeing if that SURT form begins with any of a number of SURT prefixes. (See the glossary definitions for detailed information about the SURT form of a URI and SURT prefix comparisons.)
The operator may establish the set of SURT prefixes used either by letting the SURT prefixes be implied from the supplied seed URIs, specifying an external file with a listing of SURT prefixes, or both.
This scope also enables a special syntax within the seeds list for adding SURT prefixes separate from seeds. Any line in the seeds list beginning with a '+' will be considered a SURT prefix specification, rather than a seed. Any URL you put after the '+' will only be used to deduce a SURT prefix -- it will not be independently scheduled. You can also put your own literal SURT prefix after the '+'.
For example, each of the following SURT prefix directives in the seeds box are equivalent:
+http://(org,example, # literal SURT prefix +http://example.org # regular URL implying same SURT prefix +example.org # URL fragment with implied 'http' schemeWhen you use this scope, it adds 3 hard-to-find-in-the-UI attributes --
surts-source-file,seeds-as-surt-prefixes, andsurts-dump-file-- to the end of the scope section, just aftertransitiveFilterbut beforehttp-headers.Use the
surts-source-filesetting to supply an external file from which to infer SURT prefixes, if desired. Any URLs in this file will be converted to the implied SURT prefix, and any line beginning with a '+' will be interpreted as a literal, precise SURT prefix. Use theseeds-as-surt-prefixessetting to establish whether SURT prefixes should be deduced from the seeds, in accordance with the rules given at the SURT prefix glossary entry. (The default is 'true', to deduce SURT prefixes from seeds.)To see what SURT prefixes were actually used -- perhaps merged from seed-deduced and externally-supplied -- you can specify a file path in the
surts-dump-filesetting. The sorted list of actual SURT prefixes used will be written to that file for reference. (Note that redundant entries will be removed from this dump. If you have SURT prefixes <http://(org,> and <http://(org,archive,>, only the former will actually be used, because all SURT form URIs prefixed by the latter are also prefixed by the former.)See also the crawler wiki on SurtScope.
FilterScope
A highly configurable scope. By adding different filters in different combinations this scope can be configured to provide a wide variety of behaviour.
After selecting this filter, you must then go to the Filters tab and add the filters you want to run as part of your scope. Add the filters at the focusFilter label and give them a meaningful name. The URIRegexFilter probably makes most sense in this context (The ContentTypeRegexFilter won't work at scope time because we don't know the content-type till after we've fetched the document).
After adding the filter(s), return to the Settings tab and fill in any configuration required of the filters. For example, say you added the URIRegexFilter, and you wanted only 'www.archive.org' hosts to be in focus, fill in a regex like the following:
^(?:http|dns)www.archve.org/\.*(Be careful you don't rule out prerequisites such as dns or robots.txt when specifying your scope filter).
The following scopes are available, but the same effects can be achieved more efficiently, and in combination, with SurtPrefixScope. When SurtPrefixScope can be more easily understood and configured, these scopes may be removed entirely.
DomainScope
This scope limits discovered URIs to the set of domains defined by the provided seeds. That is any URI discovered belonging to a domain from which one of the seed came is within scope. Like always it is possible to apply depth restrictions.
Using the seed 'archive.org', a domain scope will fetch 'audio.archive.org', 'movies.archive.org', etc. It will fetch all discovered URIs from 'archive.org' and from any subdomain of 'archive.org'.
HostScope
This scope limits discovered URIs to the set of hosts defined by the provided seeds.
If the seed is 'www.archive.org', then we'll only fetch items discovered on this host. The crawler will not go to 'audio.archive.org' or 'movies.archive.org'.
PathScope
This scope goes yet further and limits the discovered URIs to a section of paths on hosts defined by the seeds. Of course any host that has a seed pointing at its root (i.e.
www.sample.com/index.html) will be included in full where as a host whose only seed iswww.sample2.com/path/index.htmlwill be limited to URIs under/path/.Note
Internally Heritrix defines everything up to the right most slash as the
pathwhen doing path scope so for example, the URLshttp://members.aol.com/bigbirdandhttp://members.aol.com/~bigbirdwill treat as in scope any URL that beginsmembers.aol.com. If your intent is to only include all below the pathbigbird, add a slash on the end, using a form such ashttp://members.aol.com/bigbird/orhttp://members.aol.com/bigbird/index.htmlinstead.
Scopes usually allow for some flexibility in defining depth and possible transitive includes (that is getting items that would usually be out of scope because of special circumstance such as their being embedded in the display of an included resource). Most notably, every scope can have additional filters applied in two different contexts (some scopes may only have one these contexts).
Focus
URIs matching these filters will be considered to be within scope
Exclude
URIs matching these filters will be considered to be out of scope.
Custom made Scopes may have different sets of filters. Also some
scopes have filters hardcoded into them. This allows you to edit their
settings but not remove or replace them. For example most of the
provided scopes have a Transclusion filter
hardcoded into them that handles transitive items (URIs that normally
shouldn't be included but because of special circumstance they will be
included).
For more about Filters see Section 6.2.2, “Filters”.
Our original Scope classes -- PathScope, HostScope, DomainScope, BroadScope -- all could be thought of as fitting a specific pattern: A URI is included if and only if:
protected final boolean innerAccepts(Object o) {
return ((isSeed(o) || focusAccepts(o)) || additionalFocusAccepts(o) ||
transitiveAccepts(o)) && !excludeAccepts(o);
}More generally, the focus filter was meant to rule things in by prima facia/regexp-pattern analysis; the transitive filter rule extra items in by dynamic path analysis (for example, off site embedded images); and the exclusion filter rule things out by any number of chained exclusion rules. So in a typical crawl, the focus filter drew from one of these categories:
broad : accept all
domain: accept if on same 'domain' (for some definition) as seeds
host: accept if on exact host as seeds
path: accept if on same host and a shared path-prefix as seeds
The exclusion filter was in fact a compound chain of filters, OR'ed together, such that any one of them could knock a URI out of consideration. However, a number of aspects of this arrangement have caused problems:
To truly understand what happens to an URI, you must understand the above nested boolean-construct.
Adding mixed focuses -- such as all of this one host, all of this other domain, and then just these paths on this other host -- is not supported by these classes, nor easy to mix-in to the focus filter.
Constructing and configuring the multiple filters required many setup steps across several WUI pages.
The reverse sense of the exclusion filters -- if URIs are accepted by the filter, they are excluded from the crawl -- proved confusing, exacerbated by the fact that 'filter' itself can commonly mean either 'filter in' or 'filter out'.
As a result of these problems, the SurtPrefixScope was added, and further major changes are planned. The first steps are described in the next section, Section 6.1.1.2, “DecidingScope”. These changes will also affect whether and how filters (see Section 6.2.2, “Filters”) are used.
To address the shortcomings above, and generally make alternate scope choices more understandable and flexible, a new mechanism for scoping and filtering has been introduced in Heritrix 1.4. This new approach is somewhat like (and inspired by) HTTrack's 'scan rules'/filters, Alexa's mask/ignore/void syntax for adjusting recurring crawls, or the Nutch 'regex-urlfilter' facility, but may be a bit more general than any of those.
This new approach is available as a DecidingScope, which is modelled as a series of DecideRules. Each DecideRule, when presented with an Object (most often a URI of some form), may respond with one of three decisions:
ACCEPT: the object is ruled in
REJECT: the object is ruled out
PASS: the rule has no opinion; retain whatever previous decision was made
To define a Scope, the operator configures an ordered series of DecideRules. A URI under consideration begins with no assumed status. Each rule is applied in turn to the candidate URI. If the rule decides ACCEPT or REJECT, the URI's status is set accordingly. After all rules have been applied, if the URI's status is ACCEPT it is "in scope" and scheduled for crawling; if its status is REJECT it is discarded.
There are no branches, but much of what nested conditionals can achieve is possible, in a form that should be be easier to follow than arbitrary expressions.
The current list of available DecideRules includes:
AcceptDecideRule -- ACCEPTs all (establishing an early default)
RejectDecideRule -- REJECTs all (establishing an early default)
TooManyHopsDecideRule(max-hops=N) -- REJECTS all with hopsPath.length()>N, PASSes otherwise
PrerequisiteAcceptDecideRule -- ACCEPTs any with 'P' as last hop, PASSes otherwise (allowing prerequisites of items within other limits to also be included
MatchesRegExpDecideRule(regexp=pattern) -- ACCEPTs (or REJECTs) all matching a regexp, PASSing otherwise
NotMatchesRegExpDecideRule(regexp=pattern) -- ACCEPTs (or REJECTs) all *not* matching a regexp, PASSing otherwise.
PathologicalPathDecideRule(max-reps=N) -- REJECTs all mathing problem patterns
TooManyPathSegmentsDecideRule(max-segs=N) -- REJECTs all with too many path-segments ('/'s)
TransclusionDecideRule(extra-hops=N) -- ACCEPTs anything with up to N non-navlink (non-'L')hops at end
SurtPrefixedDecideRule(use-seeds=bool;use-file=path) -- ACCEPTs (or REJECTs) anything matched by SURT prefix set generated from supplied seeds/files/etc.
NotSurtPrefixedDecideRule(use-seeds=bool;use-file=path) -- ACCEPTs (or REJECTs) anything *not* matched by SURT prefix set generated from supplied seeds/files/etc.
OnHostsDecideRule(use-seeds=bool;use-file=path) -- ACCEPTs (or REJECTs) anything on same hosts as deduced from supplied seeds/files/etc.
NotOnHostsDecideRule(use-seeds=bool;use-file=path) -- ACCEPTs (or REJECTs) anything on *not* same hosts as deduced from supplied seeds/files/etc.
OnDomainsDecideRule(use-seeds=bool;use-file=path) -- ACCEPTs (or REJECTs) anything on same domains as deduced from supplied seeds/files/etc.
NotOnDomainsSetDecideRule(use-seeds=bool;use-file=path) -- ACCEPTs (or REJECTs) anything *not* on same domains as deduced from supplied seeds/files/etc.
MatchesFilePatternDecideRule -- ACCEPTs (or REJECTs) URIs matching a chosen predefined convenience regexp pattern (such as common file-extensions)
NotMatchesFilePatternDecideRule -- ACCEPTs (or REJECTs) URIs *not* matching a chosen predefined convenience regexp pattern
...covering just about everything our previous focus- and filter- based classes did. By ordering exclude and include actions, combinations that were awkward before -- or even impossible without writing custom code -- becomes straightforward.
For example, a previous request that was hard for us to accomodate was the idea: "crawl exactly these X hosts, and get offsite images if only on the same domains." That is, don't wander off the exact hosts to follow navigational links -- only to get offsite resources that share the same domain.
Our relevant function-of-seeds tests -- host-based and domain-based -- were exclusive of each other (at the 'focus' level) and difficult to mix-in with path-based criteria (at the 'transitive' level).
As a series of DecideRules, the above request can be easily achieved as:
RejectDecideRule
OnHostsDecideRule(use-seeds=true)
TranscludedDecideRule(extra-hops=2)
NotOnDomainsDecideRule(REJECT,use-seeds=true);
A good default set of DecideRules for many purposes would be...
RejectDecideRule // reject by default
SurtPrefixedDecideRule // accept within SURT prefixes established by seeds
TooManyHopsDecideRule // but reject if too many hops from seeds
TransclusionDecideRule // notwithstanding above, accept if within a few transcluding hops (frames/imgs/redirects)
PathologicalPathDecideRule // but reject if pathological repetitions
TooManyPathSegmentsDecideRule // ...or if too many path-segments
PrerequisiteAcceptDecideRule // but always accept a prerequisite of other URI
In Heritirx 1.10.0, the default profile was changed to use the above set of DecideRules (Previous to this, the operator had to choose the 'deciding-default' profile, since removed).
The naming, behavior, and user-interface for DecideRule-based scoping is subject to significant change based on feedback and experience in future releases.
Enable FINE logging on the class
org.archive.crawler.deciderules.DecideRuleSequence
to watch each deciderules finding on each processed URI.
The Frontier is a pluggable module that maintains the internal state of the crawl. What URIs have been discovered, crawled etc. As such its selection greatly effects, for instance, the order in which discovered URIs are crawled.
There is only one Frontier per crawl job.
Multiple Frontiers are provided with Heritrix, each of a particular character.
The default Frontier in Heritrix as of 1.4.0 and later is the BdbFrontier(Previously, the default was the Section 6.1.2.2, “HostQueuesFrontier”). The BdbFrontier visits URIs and sites discovered in a generally breadth-first manner, it offers configuration options controlling how it throttles its activity against particular hosts, and whether it has a bias towards finishing hosts in progress ('site-first' crawling) or cycling among all hosts with pending URIs.
Discovered URIs are only crawled once, except that robots.txt and DNS information can be configured so that it is refreshed at specified intervals for each host.
The main difference between the BdbFrontier and its precursor, Section 6.1.2.2, “HostQueuesFrontier”, is that BdbFrontier uses BerkeleyDB Java Edition to shift more running Frontier state to disk.
The forerunner of the Section 6.1.2.1, “BdbFrontier”. Now deprecated mostly because its custom disk-based data structures could not move as much Frontier state out of main memory as the BerkeleyDB Java Edition approach. Has same general characteristics as the Section 6.1.2.1, “BdbFrontier”.
A subclass of the Section 6.1.2.2, “HostQueuesFrontier” written by Oskar Grenholm. The DSF allows specifying an upper-bound on the number of documents downloaded per-site. It does this by exploiting Section 6.4, “Overrides” adding a filter to block further fetching once the crawler has attained per-site limits.
The AdaptiveRevisitingFrontier -- a.k.a AR Frontier -- will repeatedly visit all encountered URIs. Wait time between visits is configurable and varies based on wait intervals specified by a WaitEvaluator processor. It was written by Kristinn Sigurdsson.
Note
This Frontier is still experimental, in active development and has not been tested extensively.
In addition to the WaitEvaluator (or similar processor) a crawl using this Frontier will also need to use the ChangeEvaluator processor: i.e. this Frontier requires that ChangeEvaluator and WaitEvaluator or equivalents are present in the processing chain.
ChangeEvaluator should be at the very top of the extractor chain.
WaitEvaluator -- or an equivalent -- needs to be in the post processing chain.
The ChangeEvaluator has no configurable settings. The WaitEvaluator however has numerous settings to adjust the revisit policy.
Initial wait. A waiting period before revisiting the first time.
Increase and decrease factors on unchanged and changed documents respectively. Basically if a document has not changed between visits, its wait time will be multiplied by the "unchanged-factor" and if it has changed, the wait time will be divided by the "changed-factor". Both values accept real numbers, not just integers.
Finally, there is a 'default-wait-interval' for URIs where it is not possible to judge changes in content. Currently this applies only to DNS lookups.
If you want to specify different wait times and factors for URIs based on their mime types, this is possible. You have to create a Refinement (Section 6.5, “Refinements”) and use the ContentType criteria. Simply use a regular expression that matches the desired mime type as its parameter and then override the applicable parameters in the refinement.
By setting the 'state' directory to the same location that another AR crawl used, it should resume that crawl (minus some stats).
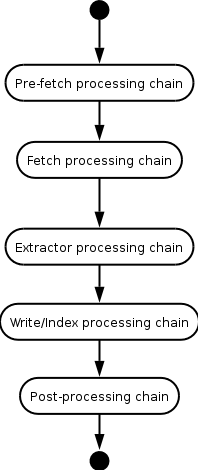
When a URI is crawled it is in fact passed through a series of processors. This series is split for convenience between five chains and the user can add, remove and reorder the processors on each of these chains.
Each URI taken off the Frontier queue runs through the
Processing Chains listed in the diagram shown
below. URIs are always processed in the order shown in the diagram
unless a particular processor throws a fatal error or decides to stop
the processing of the current URI for some reason. In this
circumstance, processing skips to the end, to the Post-processing
chain, for cleanup.
Each processing chain is made up of zero or more individual
processors. For example, the extractor processing chain might comprise
the ExtractorHTML , an
ExtractorJS , and the
ExtractorUniversal processors. Within a processing
step, the order in which processors are run is the order in which
processors are listed on the modules page.
Generally, particular processors only make sense within the
context of one particular processing chain. For example, it wouldn't
make sense to run the FetchHTTP processor in the
Post-processing chain. This is however not enforced, so users must
take care to construct logical processor chains.
Most of the processors are fairly self explanatory, however the first and last two merit a little bit more attention.
In the Pre-fetch processing chain the
following two processors should be included (or replacement modules
that perform similar operations):
Preselector
Last check if the URI should indeed be crawled. Can for example recheck scope. Useful if scope has been changed after the crawl starts (This processor is not strictly necessary).
PreconditionEnforcer
Ensures that all preconditions for crawling a URI have been met. These currently include verifying that DNS and robots.txt information has been fetched for the URI. Should always be included.
Similarly the Post Processing chain has the
following special purpose processors:
CrawlStateUpdater
Updates the per-host information that may have been affected by the fetch. This is currently robots and IP address info. Should always be included.
LinksScoper
Checks all links extracted from the current download against the crawl scope. Those that are out of scope are discarded. Logging of discarded URLs can be enabled.
FrontierScheduler
'Schedules' any URLs stored as CandidateURIs found in the current CrawlURI with the frontier for crawling. Also schedules prerequisites if any.
Any number of statistics tracking modules can be attached to a
crawl. Currently only one is provided with Heritrix. The
StatisticsTracker module that comes with Heritrix
writes the progress-statistics.log file and
provides the WUI with the data it needs to display progress
information about a crawl. It is strongly recommended that any crawl
running with the WUI use this module.
On the Submodules tab, configuration points that take variable-sized listings of components can be configured. Components can be added, ordered, and removed. Examples of such components are listings of canonicalization rules to run against each URL discovered, Section 6.2.2, “Filters” on processors, and credentials. Once submodules are added under the Submodules tab, they will show in subsequent redrawings of the Settings tab. Values which control their operation are configured over under the Settings tab.
Heritrix keeps a list of already seen URLs and before fetching,
does a look up into this 'already seen' or 'already included' list to
see if the URL has already been crawled. Often an URL can be written
in multiple ways but the page fetched is the same in each case. For
example, the page that is at
http://www.archive.org/index.html is the same page
as is at http//WWW.ARCHIVE.ORG/ though the URLs
differ (In this case by case only). Before going to the 'already
included' list, Heritrix makes an effort at equating the likes of
http://www.archive.org/index.html and
http://ARCHIVE.ORG/ by running each URL through a
set of canonicalization rules. Heritrix uses the result of this
canonicalization process when it goes to test if an URL has already
been seen.
An example of a canonicalization rule would lowercase all URLs. Another might strip the 'www' prefix from domains.
The URL Canonicalization Rules screen allows
you to specify canonicalization rules and the order in which they are
run. A default set lowercases, strips wwws, removes sessionids and
does other types of fixup such as removal of any userinfo. The URL
page works in the same manner as the Section 6.2.2, “Filters”
page.
To watch the canonicalization process, enable
org.archive.crawler.url.Canonicalizer logging in
heritrix.properties (There should already be a
commented out directive in the properties file. Search for it). Output
will show in heritrix_out.log. Set the logging
level to INFO to see just before and after the transform. Set level to
FINE to see the result of each rule's transform.
Canonicalization rules can be added as an override so an added rule only works in the overridden domain.
Canonicalization rules are NOT run if the URI-to-check is the fruit of a redirect. We do this for the following reason. Lets say the www canonicalization rule is in place (the rule that equates 'archive.org' and 'www.archive.org'). If the crawler first encounters 'archive.org' but the server at archive.org wants us to come in via 'www.archive.org', it will redirect us to 'www.archive.org'. The alreadyseen database will have been marked with 'archive.org' on the original access of 'archive.org'. The www canonicalization rule runs and makes 'archive.org' of 'www.archive.org' which has already been seen. If we always ran canonicalization rules regardless, we wouldn't ever crawl 'www.archive.org'.
Say site x.y.z is returning URLs with a session ID key of
cid as in
http://x.y.z/index.html?cid=XYZ123112232112229BCDEFFA0000111.
Say the session ID value is always 32 characters. Say also, for
simplicity's sake, that it always appears on the end of the
URL.
Add a RegexRule override for the domain x.y.z. To do this,
pause the crawl, add an override for x.y.z by clicking on the
overrides tab in the main menu bar and filling
in the domain x.y.z. Once in the override screen, click on the
URL tab in the override menu bar -- the new bar
that appears below the main bar when in override mode -- and add a
RegexRule canonicalization rule. Name it
cidStripper. Adjust where you'd like it to
appear in the running of canonicalization rules (Towards the end
should be fine). Now browse back to the override settings. The new
canonicalization rule cidStripper should appear
in the settings page list of canonicalization rules. Fill in the
RegexRule matching-regex with something like
the following: ^(.+)(?:cid=[0-9a-zA-Z]{32})?$
(Match a tail of 'cid=SOME_32_CHAR_STR' grouping all that comes
before this tail). Fill into the format field
${1} (This will copy the first group from the
regex if the regex matched). To see the rule in operation, set the
logging level for
org.archive.crawler.url.Canonicalizer in
heritrix.properties (Try uncommenting the line
org.archive.crawler.url.Canonicalizer.level =
INFO). Study the output and adjust your regex
accordingly.
See also msg1611 for another's experience getting regex to work.
Filters are modules that take a CrawlURI and determine if it matches the criteria of the filter. If so it returns true, otherwise it returns false.
Filters are used in a couple of different contexts in Heritrix.
Their use in scopes has already been discussed in Section 6.1.1, “Crawl Scope” and the problems with using them that in Section 6.1.1.1, “Problems with the current Scopes”.
Note
A DecidingFilter was added in 1.4.0 to address problems with current filter model. DecideRules can be added into a DecidingFilter with the filter decision the result of all included DecideRule set processing. There are DecideRule equivalents for all Filter-types mentioned below. See Section 6.1.1.2, “DecidingScope” for more on the particulars of DecideRules and on the new Deciding model in general.
Aside from scopes, filters are also used in processors. Filters applied to processors always filter URIs out. That is to say that any URI matching a filter on a processor will effectively skip over that processor.
This can be useful to disable (for instance) link extraction on documents coming from a specific section of a given website.
The Submodules page of the configuration section of the WUI lists existing filters along with the option to remove, add, or move Filters up or down in the listing.
Adding a new filters requires giving it a unique name (for that list), selecting the class type of the filter from a combobox and clicking the associated add button. After the filter is added, its custom settings, if any, will appear in the Settings page of the configuration UI.
Since filters can in turn contain other filters (the OrFilter being the best example of this) these lists can become quite complex and at times confusing.
The following is an overview of the most useful of the filters provided with Heritrix.
Contains any number of filters and returns true if any of them returns true. A logical OR on its filters basically.
Returns true if a URI matches the regular expression set for it. See Regular expressions for more about regular expressions in Heritrix.
This filter runs a regular expression against the response
Content-Type header. Returns true if content
type matches the regular expression. ContentType regexp filter
cannot be used until after fetcher processors have run. Only then
is the Content-Type of the response known. A good place for this
filter is the writer step in processing. See Regular expressions for more about regular expressions in
Heritrix.
Returns true if a URI is prefixed by one of the SURT prefixes supplied by an external file.
Compares suffix of a passed URI against a regular expression pattern, returns true for matches.
Returns true for all CrawlURI passed in
with a path depth less or equal to its
max-path-depth value.
Checks if a URI contains a repeated pattern.
This filter checks if a pattern is repeated a specific number of times. The use is to avoid crawler traps where the server adds the same pattern to the requested URI like:
http://host/img/img/img/img....
Returns true if such a pattern is found. Sometimes used on a processor but is primarily of use in the exclude section of scopes.
Returns true for all URIs passed in with a Link hop count greater than the
max-link-hops value.
Generally only used in scopes.
Filter which returns true for CrawlURI
instances which contain more than zero but fewer than
max-trans-hops embed entries at the end of
their Discovery path.
Generally only used in scopes.
In this section you can add login credentials that will allow Heritrix to gain access to areas of websites requiring authentication. As with all modules they are only added here (supplying a unique name for each credential) and then configured on the settings page (Section 6.3, “Settings”).
One of the settings for each credential is its
credential-domain and thus it is possible to create
all credentials on the global level. However since this can cause
excessive unneeded checking of credentials it is recommended that
credentials be added to the appropriate domain override (see Section 6.4, “Overrides” for details). That way the credential is only
checked when the relevant domain is being crawled.
Heritrix can do two types of authentication: RFC2617 (BASIC and DIGEST Auth) and POST and GET of an HTML Form.
Logging
To enable text console logging of authentication interactions (for example for debugging), set the FetchHTTP and PrconditionEnforcer log levels to fine
org.archive.crawler.fetcher.FetchHTTP.level = FINE org.archive.crawler.prefetch.PreconditionEnforcer.level = FINE
This is done by editing the
heritrix.properties file under the
conf directory as described in Section 2.2.2.1, “heritrix.properties”.
6.2.3.1. RFC2617 (BASIC and DIGEST Auth)
Supply credential-domain, realm, login, and password.
The way that the RFC2617 authentication works in Heritrix is that in response to a 401 response code (Unauthorized), Heritrix will use a key made up of the Credential Domain plus Realm to do a lookup into its Credential Store. If a match is found, then the credential is loaded into the CrawlURI and the CrawlURI is marked for immediate retry.
When the requeued CrawlURI comes around again, this time through, the found credentials are added to the request. If the request succeeds -- result code of 200 -- the credentials are promoted to the CrawlServer and all subsequent requests made against this CrawlServer will preemptively volunteer the credential. If the credential fails -- we get another 401 -- then the URI is let die a natural 401 death.
This equates to the canonical root URI of RFC2617; effectively, in our case, its the CrawlServer name or URI authority (domain plus port if other than port 80). Examples of credential-domain would be: 'www.archive.org' or 'www.archive.org:8080', etc.
Realm as per RFC2617. The realm string must match exactly the realm name presented in the authentication challenge served up by the web server
... but your mileage may vary going up against other servers (See [ 914301 ] Logging in (HTTP POST, Basic Auth, etc.) to learn more).
Supply credential-domain, http-method, login-uri, and form-items, .
Before a uri is scheduled, we look for
preconditions. Examples of preconditions are the getting of the the
dns record for the server that hosts the uri and
the fetching of the robots.txt: i.e. we don't
fetch any uri unless we first have gotten the
robots.txt file. The HTML Form Credentials are
done as a precondition. If there are HTML Form Credentials for a
particular crawlserver in the credential store, the uri specified in
the HTML Form Credential login-uri field is scheduled as a
precondition for the site, after the fetching of the dns and robots
preconditions.
Same as the Rfc22617 Credential credential-domain.
Relative or absolute URI to the page that the HTML Form submits to (Not the page that contains the HTML Form).
Listing of HTML Form key/value pairs. Don't forget to include the form submit button.
If a site has an HTML Form Credential associated, the next thing done after the getting of the dns record and the robots.txt is that a login is performed against all listed HTML Form Credential login-uris. This means that the crawler will only ever view sites that have HTML Form Credentials from the 'logged-in' perspective. There is no way currently of telling the crawler to crawl the site 'non-logged-in' and then, when done, log in and crawl the site anew only this time from the 'logged-in' perspective (At least, not as part of the one crawl job).
The login is run once only and the crawler continues whether the login succeeded or not. There is no means of telling the crawler retry upon unsuccessful authentication. Neither is there a means for the crawler to report success or otherwise (The operator is expected to study logs to see whether authentication ran successfully).
This page presents a semi-treelike representation of all the modules (fixed and pluggable alike) that make up the current configuration and allows the user to edit any of their settings. Go to the Modules and SubModules tabs to add, remove, replace modules mentioned here in the Settings page.
The first option presented directly under the top tabs is whether to hide or display 'expert settings'. Expert settings are those settings that are rarely changed and should only be changed by someone with a clear understanding of their implication. This document will not discuss any of the expert settings.
The first setting is the description of the job previously discussed. The seed list is at the bottom of the page. Between the two are all the other possible settings.
Module names are presented in bold and a short explanation of them is provided. As discussed in the previous three chapters some of them can be replaced, removed or augmented.
Behind each module and settings name a small question mark is present. By clicking on it a more detailed explanation of the relevant item pops up. For most settings users should refer to that as their primary source of information.
Some settings provide a fixed number of possible 'legal' values in combo boxes. Most are however typical text input fields. Two types of settings require a bit of additional attention.
Lists
Some settings are a list of values. In those cases a list is printed with an associated Remove button and an input box is printed below it with an Add button. Only those items in the list box are considered in the list itself. A value in the input box does not become a part of the list until the user clicks Add. There is no way to edit existing values beyond removing them and replacing them with correct values. It is also not possible to reorder the list.
Simple typed maps
Generally Maps in the Heritrix settings framework contain program modules (such as the processors for example) and are therefore edited elsewhere. However maps that only accept simple data types (Java primitives) can be edited here.
They are treated as a key, value pair. Two input boxes are provided for new entries with the first one representing the key and the second the value. Clicking the associated Add button adds the entry to the map. Above the input boxes a list of existing entries is displayed along with a Remove option. Simple maps can not be reordered.
Changes on this page are not saved until you navigate to another part of the settings framework or you click the submit job/finished tab.
If there is a problem with one of the settings a red star will appear next to it. Clicking the star will display the relevant error message.
Some settings are always present. They form the so called crawl order. The root of the settings hierarchy that other modules plug into.
In addition to limits imposed on the scope of the crawl it is possible to enforce arbitrary limits on the duration and extent of the crawl with the following settings:
max-bytes-download
Stop after a fixed number of bytes have been downloaded. 0 means unlimited.
max-document-download
Stop after downloading a fixed number of documents. 0 means unlimited.
max-time-sec
Stop after a certain number of seconds have elapsed. 0 means unlimited.
For handy reference there are 3600 seconds in an hour and 86400 seconds in a day.
Note
These are not hard limits. Once one of these limits is hit it will trigger a graceful termination of the crawl job, that means that URIs already being crawled will be completed. As a result the set limit will be exceeded by some amount.
Set the number of toe threads (see Toe Threads).
If running a domain crawl smaller than 100 hosts a value approximately twice the number of hosts should be enough. Values larger then 150-200 are rarely worthwhile unless running on machines with exceptional resources.
Currently Heritrix supports configuring the
user-agent and from fields in
the HTTP headers generated when requesting URIs from
webservers.
The initial user-agent template you see when you first start heritrix will look something like the following:
Mozilla/5.0 (compatible; heritrix/0.11.0 +PROJECT_URL_HERE
You must change at least the
PROJECT_URL_HERE and put in place a website
that webmasters can go to to view information on the organization
or person running a crawl.
The user-agent string must adhere to the
following format:
[optional-text] ([optional-text] +PROJECT_URL [optional-text]) [optional-text]
The parenthesis and plus sign before the URL must be present. Other examples of valid user agents would include:
my-heritrix-crawler (+http://mywebsite.com) Mozilla/5.0 (compatible; bush-crawler +http://whitehouse.gov) Mozilla/5.0 (compatible; os-heritrix/0.11.0 +http://loc.gov on behalf to the Library of Congress)
There are five types of policies offered on how to deal with
robots.txt rules:
classic
Simply obey the
robots.txtrules. Recommended unless you have special permission to collect a site more aggressively.ignore
Completely ignore
robots.txtrules.custom
Obey user set, custom,
robots.txtrules instead of those discovered on the relevant site.Mostly useful in overrides.
most-favored
Obey the rules set in the
robots.txtfor the robot that is allowed to access the most or has the least restrictions. Can optionally masquerade as said robot.most-favored-set
Same as 4, but limit the robots whose rules we can follow to a given set.
Note
Choosing options 3-5 requires setting additional information in the fields below the policy combobox. For options 1 and 2 those can be ignored.
The different scopes do share a few common settings. (See Section 6.1.1, “Crawl Scope” for more on scopes provided with Heritrix.)
max-link-hops
Maximum number of links followed to get to the current URI. Basically counts 'L's in the Discovery path.
max-trans-hops
Maximum number of non link hops at the end of the current URI's Discovery path. Generally we don't want to follow embeds, redirects and the like for more than a few (default 5) hops in a row. Such deep embedded structures are usually crawler traps. Since embeds are usually treated with higher priority then links, getting stuck in this type of trap can be particularly harmful to the crawl.
Additionally scopes may possess many more settings, depending on what filters are attached to them. See the related pop-up help in the WUI for information on those.
The Frontier provided with Heritrix has a few settings of particular interest.
A combination of four settings controls the politeness of the Frontier. Before we cover them it is important to note that at any given time only one URI from any given Host is being processed. The following politeness rules all revolve around imposing additional wait time between the end of processing one URI and until the next one starts.
delay-factor
Imposes a delay between URIs from the same host that is a multiple of the amount of time it took to fetch the last URI downloaded from that host.
For example if it took 800 milliseconds to fetch the last URI from a host and the delay-factor is 5 (a very high value) then the Frontier will wait 4000 milliseconds (4 seconds) before allowing another URI from that host to be processed.
This value can be set to 0 for maximum impoliteness. It is never possible to have multiple concurrent URIs being processed from the same host.
max-delay-ms
This setting allows the user to set a maximum upper limit on the 'in between URIs' wait created by the delay factor. If set to 1000 milliseconds then in the example used above the Frontier would only hold URIs from that host for 1 second instead of 4 since the delay factor exceeded this ceiling value.
min-delay-ms
Similar to the maximum limit, this imposes a minimum limit to the politeness. This can be useful to ensure, for example, that at least 100 milliseconds elapse between connections to the same host. In a case where the delay factor is 2 and it only took 20 milliseconds to get a URI this would come into effect.
min-interval-ms
An alternate way of putting a floor on the delay, this specifies the minimum number of milliseconds that must elapse from the start of processing one URI until the next one after it starts. This can be useful in cases where sites have a mix of large files that take an excessive amount of time and very small files that take virtually no time.
In all cases (this can vary from URI to URI) the more restrictive (delaying) of the two floor values is imposed.
The Frontier imposes a policy on retrying URIs that encountered errors that usually are transitory (socket timeouts etc.) . Fetcher processors may also have their own policies on certain aspects of this.
max-retries
How often to retry URIs that encounter possible transient errors.
retry-delay-seconds
How long to wait between such retries.
The Frontier allows the user to limit bandwidth usage. This is done by holding back URIs when bandwidth usage has exceeded limits. As a result individual spikes of bandwidth usage can occur that greatly exceed this limit. This only limits overall bandwidth usage over a longer period of time (minutes).
total-bandwidth-usage-KB-sec
Maximum bandwidth to use in Kilobytes per second.
max-per-host-bandwidth-usage-KB-sec
Maximum bandwidth to use in dealing with any given host. This is a form of politeness control as it limits the load Heritrix places on a host.
A couple of the provided processors have settings that merit some extra attention.
As has been noted elsewhere each processor has a setting named enabled. This is set to true by default, but can be set to false to effectively remove it from consideration. Processors whose enabled setting is set to false will not be applied to any applicable URI (this is of greatest use in overrides and refinements).
timeout-seconds
If a fetch is not completed within this many seconds, the HTTP fetcher will terminate it.
Should generally be set quite high.
max-length-bytes
Maximum number of bytes to download per document. Will truncate file once this limit is reached.
By default this value is set to an extremely large value (in the exabyte range) that will never be reached in practice.
Its also possible to add in filters that are
checked after the download of the HTTP response headers but before
the response content is read. Use
midfetch-filters to abort the download of
content-types other than those wanted (Aborted fetches have an
annotation midFetchAbort appended to the
crawl.log entry). Note that unless the same
filters are applied at the writer processing step, the response
headers -- but not the content -- will show in ARC files.
The ARC writer processor can be configured somewhat. This mostly relates to how the ARC files are written to disk.
compress
Write compressed ARC files true or false.
Note
Each item that is added to the ARC file will be compressed individually.
prefix
A prefix to the ARC files filename. See Section 9.1.9, “ARC files” for more on ARC file naming.
max-size-bytes
Maximum size per ARC file. Once this size is reached no more documents will be added to an ARC file, another will be created to continue the crawl. This is of course not a hard limit and the last item added to an ARC file will push its size above this limit. If exceptionally large items are being downloaded the size of an ARC file may exceed this value by a considerable amount since items will never be split between ARC files.
path
Path where ARC files should be written. Can be a list of absolute paths. If relative paths, will be relative to the
jobdirectory. It can be safely configured mid-crawl to point elsewhere if current location is close to full. If multiple paths, then we'll choose from the list of paths in a round-robin fashion.pool-max-active
The Archiver maintains a pool of ARC files which are each ready to accept a downloaded documents, to prevent ARC writing from being a bottleneck in multithreaded operation. This setting establishes the maximum number of such files to keep ready. Default is 5. For small crawls that you want to confine to a single ARC file, this should be set to 1.
pool-max-wait
The maximum amount of time to wait on the Archiver's pool element.
Overrides provide the ability to override individual settings on a per domain basis. The overrides page provides an iterative list of domains that contain override settings, that is values for parameters that override values in the global configuration.
It is best to think of the general global settings as the root of the settings hierarchy and they are then overridden by top level domains (com, net, org, etc) who are in turn overridden by domains (yahoo.com, archive.org, etc.) who can further be overridden by subdomains (crawler.archive.org). There is no limit for how deep into the subdomains the overrides can go.
When a URI is being processed the settings for its host is first looked up. If the needed setting is not available there, its super domains are checked until the setting is found (all settings exist at the global level at the very least).
Creating a new override is done by simply typing in the domain in the input box at the bottom of the page and clicking the Create / Edit button. Alternatively if overrides already exist the user can navigate the hierarchy of existing overrides, edit them and create new overrides on domains that don't already have them.
Once an override has been created or selected for editing the user is taken to a page that closely resembles the settings page discussed in Section 6.3, “Settings”. The main difference is that those settings that can not be overridden (file locations, number of threads etc.) are printed in a non-editable manner. Those settings that can be edited now have a checkbox in front of them. If they are being overridden at the current level that checkbox should be checked. Editing a setting will cause the checkmark to appear. Removing the checkmark effectively removes the override on that setting.
Once on the settings page the second level tabs will change to override context. The new tabs will be similar to the general tabs and will have:
URL
Add URL Canonicalization Rules to the override. It is not possible to remove inherited filters or interject new filters among them. New filters will be added after existing filters.
Filters
Add filters to the override. It is not possible to remove inherited filters or interject new filters among them. New filters will be added after existing filters.
Inherited filters though have the option to locally disable them. That can be set on the settings page.
Credentials
Add credentials to the override. Generally credentials should always be added to an override of the domain most relevant to them. See Section 6.2.3, “Credentials” for more details.
Settings
Page allowing the user to override specific settings as discussed above.
Refinements
Manage refinements for the override. See Section 6.5, “Refinements”
Done with override
Once the user has finished with the override, this option will take him back to the overrides overview page.
It is not possible to add, remove or reorder existing modules on an override. It is only possible to add filters and credentials. Those added will be inherited to sub domains of the current override domain. Those modules that are added in an override will not have a checkbox in front of their settings on the override settings page since the override is effectively their 'root'.
Finally, due to how the settings framework is structured there is negligible performance penalty to using overrides. Lookups for settings take as much time whether or not overrides have been defined. For URIs belonging to domains without overrides no performance penalty is incurred.
Refinements are similar to overrides (see Section 6.4, “Overrides”) in that they allow the user to modify the settings under certain circumstances. There are however two major differences.
Refinements are applied based on arbitrary criteria rather then encountered URIs domain.
Currently it is possible to set criteria based on the time of day, a regular expression matching the URI and the port number of the URI.
They incur a performance penalty.
This effect is small if their numbers are few but for each URI encountered there must be a check made to see if it matches any of the existing criteria of defined refinements.
This effect can be mitigated by applying refinements to overrides rather then the global settings.
Refinements can be applied either to the global settings or to any override. If applied to an override they can affect any settings, regardless of whether the parent override has modified it.
It is not possible to create refinements on refinements.
Clicking the Refinements tab on either the global settings or an override brings the user to the refinements overview page. The overview page displays a list of existing refinements on the current level and allows the user to create new ones.
To create a new refinement the user must supply a unique name for it (name is limited to letters, numbers, dash and underscore) and a short description that will be displayed underneath it on the overview page.
Once created, refinements can be either removed or edited.
Choosing the edit option on an override brings the user to the criteria page. Aside from the criteria tab replacing the refinements tab, the second level tabs will have the same options as they do for overrides and their behavior will be the same. Clicking the 'Done with refinement' tab will bring the user back to the refinements overview page.
The criteria page displays a list of the current criteria and the option to add any of the available criteria types to the list. It is also possible to remove existing criteria.
Note
URIs must match all set criteria for the refinement to take effect.
Currently the following criteria can be applied:
Port number
Match only those URIs for the given port number.
Default port number for HTTP is 80 and 443 for HTTPS.
Time of day
If this criteria is applied the refinement will be in effect between the hours specified each day.
The format for the input boxes is HHMM (hours and minutes).
An example might be: From 0200, To 0600. This refinement would be in effect between 2 and 6 am each night. Possibly to ease the politeness requirements during these hours when load on websites is generally low.
Note
As with all times in Heritrix these are always GMT times.
Regular expression
The refinement will only be in effect for those URIs that match the given regular expression.
Note
See Regular expressions for more on them.