The Heritrix Web Crawler is designed to be modular. Which modules to use can be set at runtime from the user interface. Our hope is that if you want the crawler to behave different from the default, it should only be a matter of writing a new module as a replacement or in addition to the modules shipped with the crawler.
The rest of this document assumes you have a basic understanding of how to run a crawl (see: [Heritrix User Guide]). Since the crawler is written in the Java programming language, you also need a fairly good understanding of Java.
The crawler consists of core classes and pluggable modules. The core classes can be configured, but not replaced. The pluggable classes can be substituted by altering the configuration of the crawler. A set of basic pluggable classes are shipped with the crawler, but if you have needs not met by these classes you could write your own.
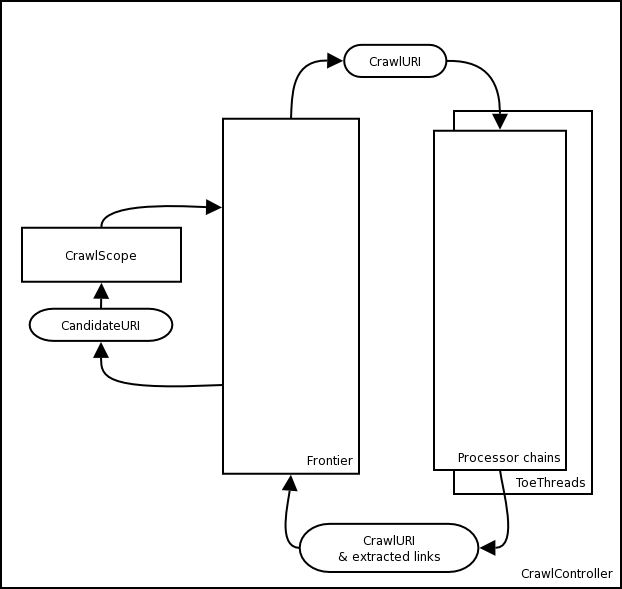
The CrawlController collects all the classes which cooperate to perform a crawl, provides a high-level interface to the running crawl, and executes the "master thread" which doles out URIs from the Frontier to the ToeThreads. As the "global context" for a crawl, subcomponents will usually reach each other through the CrawlController.
The Frontier is responsible for handing out the next URI to be crawled. It is responsible for maintaining politeness, that is making sure that no web server is crawled too heavily. After a URI is crawled, it is handed back to the Frontier along with any newly discovered URIs that the Frontier should schedule for crawling.
It is the Frontier which keeps the state of the crawl. This includes, but is not limited to:
What URIs have been discovered
What URIs are being processed (fetched)
What URIs have been processed
The Frontier implements the Frontier interface and can be replaced by any Frontier that implements this interface. It should be noted though that writing a Frontier is not a trivial task.
The Frontier relies on the behavior of at least the following external processors: PreconditionEnforcer, LinksScoper and the FrontierScheduler (See below for more each of these Processors). The PreconditionEnforcer makes sure dns and robots are checked ahead of any fetching. LinksScoper tests if we are interested in a particular URL -- whether the URL is 'within the crawl scope' and if so, what our level of interest in the URL is, the priority with which it should be fetched. The FrontierScheduler adds ('schedules') URLs to the Frontier for crawling.
The Heritrix web crawler is multi threaded. Every URI is handled by its own thread called a ToeThread. A ToeThread asks the Frontier for a new URI, sends it through all the processors and then asks for a new URI.
Processors are grouped into processor chains (Figure 2, “Processor chains”). Each chain does some processing on a URI. When a Processor is finished with a URI the ToeThread sends the URI to the next Processor until the URI has been processed by all the Processors. A processor has the option of telling the URI to skip to a particular chain. Also if a processor throws a fatal error, the processing skips to the Post-processing chain.
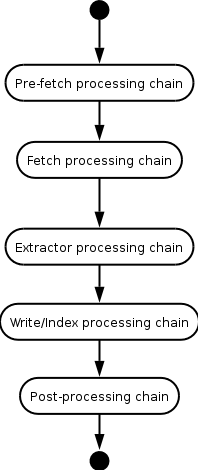
The task performed by the different processing chains are as follows:
The first chain is responsible for investigating if the URI could be crawled at this point. That includes checking if all preconditions are met (DNS-lookup, fetching robots.txt, authentication). It is also possible to completely block the crawling of URIs that have not passed through the scope check.
In the Pre-fetch processing chain the
following processors should be included (or replacement modules that
perform similar operations):
Preselector
Last check if the URI should indeed be crawled. Can for example recheck scope. Useful if scope rules have been changed after the crawl starts. The scope is usually checked by the LinksScoper, before new URIs are added to the Frontier to be crawled. If the user changes the scope limits, it will not affect already queued URIs. By rechecking the scope at this point, you make sure that only URIs that are within current scope are being crawled.
PreconditionEnforcer
Ensures that all preconditions for crawling a URI have been met. These currently include verifying that DNS and robots.txt information has been fetched for the URI.
The processors in this chain are responsible for getting the data from the remote server. There should be one processor for each protocol that Heritrix supports: e.g. FetchHTTP.
At this point the content of the document referenced by the URI is available and several processors will in turn try to get new links from it.
This chain is responsible for writing the data to archive files. Heritrix comes with an ARCWriterProcessor which writes to the ARC format. New processors could be written to support other formats and even create indexes.
A URI should always pass through this chain even if a decision not to crawl the URI was done in a processor earlier in the chain. The post-processing chain must contain the following processors (or replacement modules that perform similar operations):
CrawlStateUpdater
Updates the per-host information that may have been affected by the fetch. This is currently robots and IP address info.
LinksScoper
Checks all links extracted from the current download against the crawl scope. Those that are out of scope are discarded. Logging of discarded URLs can be enabled.
FrontierScheduler
'Schedules' any URLs stored as CandidateURIs found in the current CrawlURI with the frontier for crawling. Also schedules prerequisites if any.