As mentioned before, the Frontier is a pluggable module responsible for deciding which URI to process next, and when. The Frontier is also responsible for keeping track of other aspects of the crawls internal state which in turn can be used for logging and reporting. Even though the responsibilities of the Frontier might not look overwhelming, it is one of the hardest modules to write well. You should really investigate if your needs could not be met by the existing Frontier, or at least mostly met by subclassing an existing Frontier. With these warnings in mind, let's go ahead and create a really simple Frontier.
package mypackage;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.archive.crawler.datamodel.CandidateURI;
import org.archive.crawler.datamodel.CrawlURI;
import org.archive.crawler.datamodel.FetchStatusCodes;
import org.archive.crawler.datamodel.UURI;
import org.archive.crawler.framework.CrawlController;
import org.archive.crawler.framework.Frontier;
import org.archive.crawler.framework.FrontierMarker;
import org.archive.crawler.framework.exceptions.FatalConfigurationException;
import org.archive.crawler.framework.exceptions.InvalidFrontierMarkerException;
import org.archive.crawler.settings.ModuleType;
/**
* A simple Frontier implementation for tutorial purposes
*/
public class MyFrontier extends ModuleType implements Frontier,
FetchStatusCodes {
// A list of the discovered URIs that should be crawled.
List pendingURIs = new ArrayList();
// A list of prerequisites that needs to be met before any other URI is
// allowed to be crawled, e.g. DNS-lookups
List prerequisites = new ArrayList();
// A hash of already crawled URIs so that every URI is crawled only once.
Map alreadyIncluded = new HashMap();
// Reference to the CrawlController.
CrawlController controller;
// Flag to note if a URI is being processed.
boolean uriInProcess = false;
// top-level stats
long successCount = 0;
long failedCount = 0;
long disregardedCount = 0;
long totalProcessedBytes = 0;
public MyFrontier(String name) {
super(Frontier.ATTR_NAME, "A simple frontier.");
}
public void initialize(CrawlController controller)
throws FatalConfigurationException, IOException {
this.controller = controller;
// Initialize the pending queue with the seeds
this.controller.getScope().refreshSeeds();
List seeds = this.controller.getScope().getSeedlist();
synchronized(seeds) {
for (Iterator i = seeds.iterator(); i.hasNext();) {
UURI u = (UURI) i.next();
CandidateURI caUri = new CandidateURI(u);
caUri.setSeed();
schedule(caUri);
}
}
}
public synchronized CrawlURI next(int timeout) throws InterruptedException {
if (!uriInProcess && !isEmpty()) {
uriInProcess = true;
CrawlURI curi;
if (!prerequisites.isEmpty()) {
curi = CrawlURI.from((CandidateURI) prerequisites.remove(0));
} else {
curi = CrawlURI.from((CandidateURI) pendingURIs.remove(0));
}
curi.setServer(controller.getServerCache().getServerFor(curi));
return curi;
} else {
wait(timeout);
return null;
}
}
public boolean isEmpty() {
return pendingURIs.isEmpty() && prerequisites.isEmpty();
}
public synchronized void schedule(CandidateURI caURI) {
// Schedule a uri for crawling if it is not already crawled
if (!alreadyIncluded.containsKey(caURI.getURIString())) {
if(caURI.needsImmediateScheduling()) {
prerequisites.add(caURI);
} else {
pendingURIs.add(caURI);
}
alreadyIncluded.put(caURI.getURIString(), caURI);
}
}
public void batchSchedule(CandidateURI caURI) {
schedule(caURI);
}
public void batchFlush() {
}
public synchronized void finished(CrawlURI cURI) {
uriInProcess = false;
if (cURI.isSuccess()) {
successCount++;
totalProcessedBytes += cURI.getContentSize();
controller.fireCrawledURISuccessfulEvent(cURI);
cURI.stripToMinimal();
} else if (cURI.getFetchStatus() == S_DEFERRED) {
cURI.processingCleanup();
alreadyIncluded.remove(cURI.getURIString());
schedule(cURI);
} else if (cURI.getFetchStatus() == S_ROBOTS_PRECLUDED
|| cURI.getFetchStatus() == S_OUT_OF_SCOPE
|| cURI.getFetchStatus() == S_BLOCKED_BY_USER
|| cURI.getFetchStatus() == S_TOO_MANY_EMBED_HOPS
|| cURI.getFetchStatus() == S_TOO_MANY_LINK_HOPS
|| cURI.getFetchStatus() == S_DELETED_BY_USER) {
controller.fireCrawledURIDisregardEvent(cURI);
disregardedCount++;
cURI.stripToMinimal();
} else {
controller.fireCrawledURIFailureEvent(cURI);
failedCount++;
cURI.stripToMinimal();
}
cURI.processingCleanup();
}
public long discoveredUriCount() {
return alreadyIncluded.size();
}
public long queuedUriCount() {
return pendingURIs.size() + prerequisites.size();
}
public long finishedUriCount() {
return successCount + failedCount + disregardedCount;
}
public long successfullyFetchedCount() {
return successCount;
}
public long failedFetchCount() {
return failedCount;
}
public long disregardedFetchCount() {
return disregardedCount;
}
public long totalBytesWritten() {
return totalProcessedBytes;
}
public String report() {
return "This frontier does not return a report.";
}
public void importRecoverLog(String pathToLog) throws IOException {
throw new UnsupportedOperationException();
}
public FrontierMarker getInitialMarker(String regexpr,
boolean inCacheOnly) {
return null;
}
public ArrayList getURIsList(FrontierMarker marker, int numberOfMatches,
boolean verbose) throws InvalidFrontierMarkerException {
return null;
}
public long deleteURIs(String match) {
return 0;
}
}Note
To test this new Frontier you must add it to the classpath. Then
to let the user interface be aware of it, you must add the fully
qualified classname to the
Frontier.options file in the
conf/modules
directory.
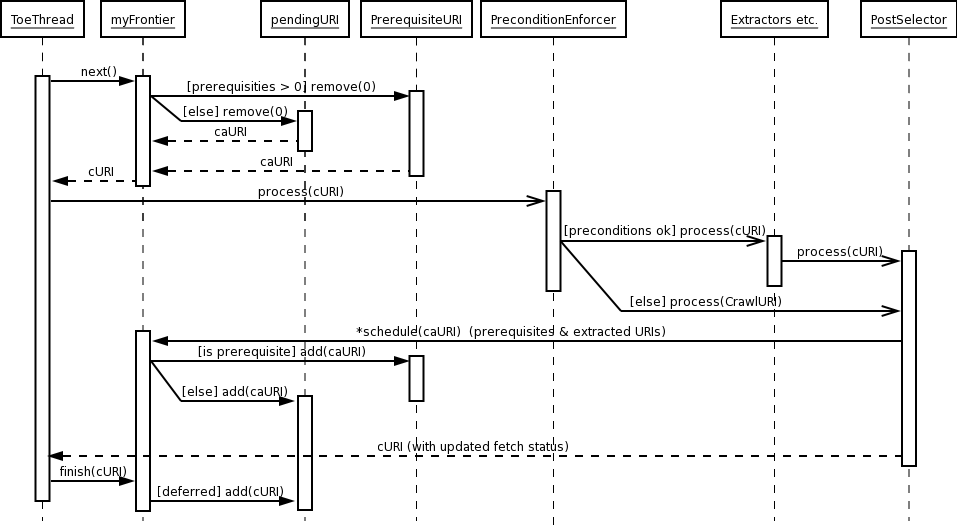
This Frontier hands out the URIs in the order they are discovered, one at a time. To make sure that the web servers are not overloaded it waits until a URI is finished processing before it hands out the next one. It does not retry URIs for other reasons than prerequisites not met (DNS lookup and fetching of robots.txt). This Frontier skips a lot of the tasks a real Frontier should take care of. The first thing is that it doesn't log anything. A real Frontier would log what happened to every URI. A real Frontier would also be aware of the fact that Heritrix is multi threaded and try to process as many URIs simultaneously as allowed by the number of threads without breaking the politeness rules. Take a look at Frontier (javadoc) to see how a full blown Frontier might look like.
All Frontiers must implement the Frontier interface. Most Frontiers will also implement the FetchStatusCodes because these codes are used to determine what to do with a URI after it has returned from the processing cycle. In addition you might want to implement the CrawlStatusListener which enables the Frontier to be aware of starts, stops, and pausing of a crawl. For this simple example we don't care about that. The most important methods in the Frontier interface are:
next(int timeout)
schedule(CandidateURI caURI)
finished(CrawlURI cURI)
public synchronized CrawlURI next(int timeout) throws InterruptedException {
if (!uriInProcess && !isEmpty()) {  uriInProcess = true;
CrawlURI curi;
if (!prerequisites.isEmpty()) {
uriInProcess = true;
CrawlURI curi;
if (!prerequisites.isEmpty()) {  curi = CrawlURI.from((CandidateURI) prerequisites.remove(0));
} else {
curi = CrawlURI.from((CandidateURI) pendingURIs.remove(0));
}
curi.setServer(controller.getServerCache().getServerFor(curi));
curi = CrawlURI.from((CandidateURI) prerequisites.remove(0));
} else {
curi = CrawlURI.from((CandidateURI) pendingURIs.remove(0));
}
curi.setServer(controller.getServerCache().getServerFor(curi));  return curi;
} else {
wait(timeout);
return curi;
} else {
wait(timeout);  return null;
}
}
return null;
}
} | | First we check if there is a URI in process already, then check if there are any URIs left to crawl. |
| | Make sure that we let the prerequisites be processed before any regular pending URI. This ensures that DNS-lookups and fetching of robots.txt is done before any "real" data is fetched from the host. Note that DNS-lookups are treated as an ordinary URI from the Frontier's point of view. The next lines pulls a CandidateURI from the right list and turn it into a CrawlURI suitable for being crawled. The CrawlURI.from(CandidateURI) method is used because the URI in the list might already be a CrawlURI and could then be used directly. This is the case for URIs where the preconditions was not met. As we will see further down these URIs are put back into the pending queue. |
| | This line is very important. Before a CrawlURI can be processed it must be associated with a CrawlServer. The reason for this, among others, is to be able to check preconditions against the URI's host (for example so that DNS-lookups are done only once for each host, not for every URI). |
| | In this simple example, we are not being aware of the fact that Heritrix is multithreaded. We just let the method wait the timeout time and the return null if no URIs where ready. The intention of the timeout is that if no URI could be handed out at this time, we should wait the timeout before returning null. But if a URI becomes available during this time it should wake up from the wait and hand it out. See the javadoc for next(timeout) to get an explanation. |
When a URI has been sent through the processor chain it ends up in the LinksScoper. All URIs should end up here even if the preconditions where not met and the fetching, extraction and writing to the archive has been postponed. The LinksScoper iterates through all new URIs (prerequisites and/or extracted URIs) added to the CrawlURI and, if they are within the scope, converts them from Link objects to CandidateURI objects. Later in the postprocessor chain, the FrontierScheduler adds them to Frontier by calling the schedule(CandidateURI) method. There is also a batch version of the schedule method for efficiency, see the javadoc for more information. This simple Frontier treats them the same.
public synchronized void schedule(CandidateURI caURI) {
// Schedule a uri for crawling if it is not already crawled
if (!alreadyIncluded.containsKey(caURI.getURIString())) {
if(caURI.needsImmediateScheduling()) {
prerequisites.add(caURI);
} else {
pendingURIs.add(caURI);
}
alreadyIncluded.put(caURI.getURIString(), caURI);
}
} After all the processors are finished (including the FrontierScheduler's scheduling of new URIs), the ToeThread calls the Frontiers finished(CrawlURI) method submitting the CrawlURI that was sent through the chain.
public synchronized void finished(CrawlURI cURI) {
uriInProcess = false;
if (cURI.isSuccess()) {
successCount++;
totalProcessedBytes += cURI.getContentSize();
controller.fireCrawledURISuccessfulEvent(cURI);
cURI.stripToMinimal();
} else if (cURI.getFetchStatus() == S_DEFERRED) {
cURI.processingCleanup();  alreadyIncluded.remove(cURI.getURIString());
schedule(cURI);
} else if (cURI.getFetchStatus() == S_ROBOTS_PRECLUDED
alreadyIncluded.remove(cURI.getURIString());
schedule(cURI);
} else if (cURI.getFetchStatus() == S_ROBOTS_PRECLUDED  || cURI.getFetchStatus() == S_OUT_OF_SCOPE
|| cURI.getFetchStatus() == S_BLOCKED_BY_USER
|| cURI.getFetchStatus() == S_TOO_MANY_EMBED_HOPS
|| cURI.getFetchStatus() == S_TOO_MANY_LINK_HOPS
|| cURI.getFetchStatus() == S_DELETED_BY_USER) {
controller.fireCrawledURIDisregardEvent(cURI);
|| cURI.getFetchStatus() == S_OUT_OF_SCOPE
|| cURI.getFetchStatus() == S_BLOCKED_BY_USER
|| cURI.getFetchStatus() == S_TOO_MANY_EMBED_HOPS
|| cURI.getFetchStatus() == S_TOO_MANY_LINK_HOPS
|| cURI.getFetchStatus() == S_DELETED_BY_USER) {
controller.fireCrawledURIDisregardEvent(cURI);  disregardedCount++;
cURI.stripToMinimal();
disregardedCount++;
cURI.stripToMinimal();  } else {
} else {  controller.fireCrawledURIFailureEvent(cURI);
controller.fireCrawledURIFailureEvent(cURI);  failedCount++;
cURI.stripToMinimal();
failedCount++;
cURI.stripToMinimal();  }
cURI.processingCleanup();
}
cURI.processingCleanup();  }
}The processed URI will have status information attached
to it. It is the task of the finished method to check these statuses and
treat the URI according to that (see Section 2, “The Frontiers handling of dispositions”).| | If the URI was successfully crawled we update some counters for statistical purposes and "forget about it". |
| | Modules can register with the controller to receive notifications when decisions are made on how to handle a CrawlURI. For example the StatisticsTracker is dependent on these notifications to report the crawler's progress. Different fireEvent methods are called on the controller for each of the different actions taken on the CrawlURI. |
| | We call the stripToMinimal method so that all data structures referenced by the URI are removed. This is done so that any class that might want to serialize the URI could be do this as efficient as possible. |
| | If the URI was deferred because of a unsatisfied precondition, reschedule it. Also make sure it is removed from the already included map. |
| | This method nulls out any state gathered during processing. |
| | If the status is any of the one in this check, we treat it as disregarded. That is, the URI could be crawled, but we don't want it because it is outside some limit we have defined on the crawl. |
| | If it isn't any of the previous states, then the crawling of this URI is regarded as failed. We notify about it and then forget it. |